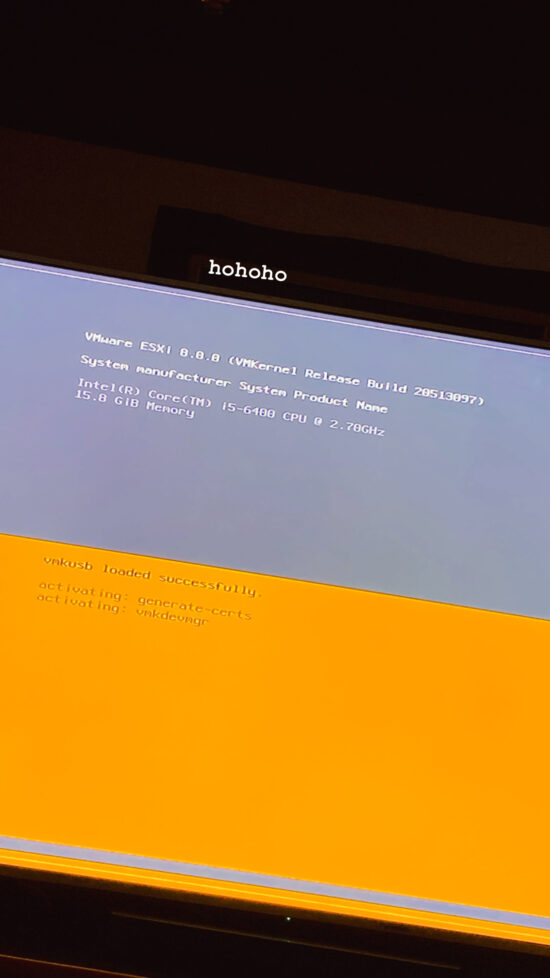
So, my friend wanted to host a forum for some group/club project that they were working on. Long story short, my friend decided to use this project: https://www.talkyard.io as his forum platform of choice. Now, he hosted the project on AWS initially, as the project was x86 only. However, this proved to be somewhat of an annoyance as the forum requires quite a fair bit of resource to run due to Java and other stuff, and ARM server, cost-wise, are much cheaper.
At the time I was bugging my friend to use OCI, as they offer a free tier which is REALLY good. However, since OCI free tier is ARM based, Talkyard, being x86 only, is a problem. My friend was kinda busy at the time and didn’t have the time to deal with it, hence I ‘graciously’ offered my help to figure out a way to port it to ARM.
Stage 1: Understanding the Problem
To install talkyard, the simplest way is to follow this guide on their GitHub: https://github.com/debiki/talkyard-prod-one
This guides you to install the production Talkyard onto your server. A quick glance and you’d notice that it uses docker-compose to build the server. From the docker-compose file, we could see that it pulls its image from docker hub, but the bad news is that the image is only for x86-64.
# Dockerfiles for the Docker images are in another Git repo:
# https://github.com/debiki/talkyard, at: images/(image-name)/Dockerfile
#
# There's an image build script: https://github.com/debiki/talkyard/blob/master/Makefile,
# the `prod-images` and `tag-and-push-latest-images` targets.
version: '3.7'
networks:
# This netw name get prefixed with COMPOSE_PROJECT_NAME = 'talkyard_' by Docker, from .env.
internal_net:
driver: bridge
ipam:
config:
- subnet: ${INTERNAL_NET_SUBNET}
services:
web:
image: ${DOCKER_REPOSITORY}/talkyard-web:${VERSION_TAG}
# dockerfile: https://github.com/debiki/talkyard/blob/master/images/web/Dockerfile
restart: always
volumes:
# The LetsEncrypt ACME account key gets generated by run-envsubst-gen-keys.sh.
# Once done, you could make this dir read-only: append ':ro' to the next line.
- ./conf/acme/:/etc/nginx/acme/
- ./conf/sites-enabled-manual/:/etc/nginx/sites-enabled-manual/:ro
- ./data/sites-enabled-auto-gen/:/etc/nginx/sites-enabled-auto-gen/:ro
- ./data/certbot/:/etc/certbot/:ro
- ./data/certbot-challenges/.well-known/:/opt/nginx/html/.well-known/:ro
- ./data/uploads/:/opt/talkyard/uploads/:ro
# Mount here so standard monitoring tools looking for Nginx logs will work.
- /var/log/nginx/:/var/log/nginx/
ports:
- '80:80'
- '443:443'
networks:
internal_net:
ipv4_address: ${INTERNAL_NET_WEB_IP}
depends_on:
- app
environment:
## By default, Talkyard logs to /var/log/nginx/ — see the volumes list above.
## However you can log to stdout instead: (both Nginx' access and error logs)
# TY_LOG_TO_STDOUT_STDERR: '1'
TY_NGX_ERROR_LOG_LEVEL: 'info' # or 'notice' or 'debug'
# TY_NGX_ACCESS_LOG_CONFIG: 'tyalogfmt'
## Max uploaded file size, e.g. uploaded images or backups to restore:
# TY_NGX_LIMIT_REQ_BODY_SIZE: '25m'
## To let any CDN of yours bypass Ty's Nginx rate limits:
# X_PULL_KEY: '...'
# CDN_PULL_KEY: '...'
# SECURITY COULD drop capabilities, see: http://rhelblog.redhat.com/2016/10/17/secure-your-containers-with-this-one-weird-trick/
# Ask at Hacker News: which caps can I drop for an Nginx container? A JVM appserver?
# Asked here about Nginx:
# https://stackoverflow.com/questions/43467670/which-capabilities-can-i-drop-in-a-docker-nginx-container
# For all containers, not just 'web'.
#cap_drop:
# - DAC_OVERRIDE
# ... many more?
app:
image: ${DOCKER_REPOSITORY}/talkyard-app:${VERSION_TAG}
# dockerfile: https://github.com/debiki/talkyard/blob/master/images/app/Dockerfile.prod
restart: always
stdin_open: true # otherwise Play Framework exits
volumes:
- ./conf/play-framework.conf:/opt/talkyard/app/conf/app-prod-override.conf:ro # see [4WDKPU2] in debiki/talkyard
- ./data/uploads/:/opt/talkyard/uploads/
# So backups can be downloaded via the admin web interface. But read-only,
# so evil bugs cannot destroy all backups.
- /opt/talkyard-backups/:/opt/talkyard-backups/:ro
# Mount here so log monitoring agents like fluentd can access the log.
- /var/log/talkyard/:/var/log/talkyard/
networks:
internal_net:
ipv4_address: ${INTERNAL_NET_APP_IP}
depends_on:
- cache
- rdb
- search
environment:
- PLAY_SECRET_KEY
- TALKYARD_SECURE
- POSTGRES_PASSWORD
- TALKYARD_HOSTNAME
- BECOME_OWNER_EMAIL_ADDRESS
cache:
image: ${DOCKER_REPOSITORY}/talkyard-cache:${VERSION_TAG}
# dockerfile: https://github.com/debiki/talkyard/blob/master/images/cache/Dockerfile
restart: always
volumes:
- ./data/cache/:/data/
- /var/log/redis/:/var/log/redis/
networks:
internal_net:
ipv4_address: ${INTERNAL_NET_CACHE_IP}
sysctls:
net.core.somaxconn: 511
rdb:
image: ${DOCKER_REPOSITORY}/talkyard-rdb:${VERSION_TAG}
# dockerfile: https://github.com/debiki/talkyard/blob/master/images/rdb/Dockerfile
restart: always
volumes:
- ./data/rdb/:/var/lib/postgresql/data/
- ./conf/rdb/:/var/lib/postgresql/conf/
# Mount here so standard monitoring tools configured to find Postgres logs here will work.
# (Inside the container, we don't mount in /var/lib/postgresql/data/pg_log/ because
# then Postgres would refuse to create a db in data/, because data/ wouldn't be empty.)
- /var/log/postgresql/:/var/log/postgresql/
networks:
internal_net:
ipv4_address: ${INTERNAL_NET_RDB_IP}
## To log to stderr instead of /var/log/postgresql/:
#command: '--logging_collector=off'
environment:
POSTGRES_PASSWORD: '$POSTGRES_PASSWORD'
# Optionally, streaming replication peer:
# (but you'll need to rename ./postgres-data/recovery.conf.disabled first — and
# that file isn't created until you start Postgres)
# PEER_HOST: 'postgres2'
# PEER_PORT: '5432'
# PEER_PASSWORD: '...'
search:
image: ${DOCKER_REPOSITORY}/talkyard-search:${VERSION_TAG}
# dockerfile: https://github.com/debiki/talkyard/blob/master/images/search/Dockerfile
restart: always
volumes:
# COULD_OPTIMIZE Maybe use a Docker volume contanier here instead? What does the docs mean when
# they say "Always use a volume bound on /usr/share/elasticsearch/data" — is mapping
# a directory from the OS okay then? (that's using (parts of) a host's device/volume.
# https://www.elastic.co/guide/en/elasticsearch/reference/5.5/docker.html#docker-cli-run-prod-mode
- ./data/search/:/usr/share/elasticsearch/data/
- /var/log/elasticsearch/:/usr/share/elasticsearch/logs/
networks:
internal_net:
ipv4_address: ${INTERNAL_NET_SEARCH_IP}
environment:
bootstrap.memory_lock: 'true'
ES_JAVA_OPTS: '-Xms512m -Xmx512m'
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
# vim: et ts=2 sw=2Well, the solution seems simple enough right? Just build the image on ARM and bam! Problem solved, right??? Well, uhmm… yes and no…
PS: I know this is a REALLY long post, and most of the time it might just be me being dumb or just fooling around. Sorry if this hurts your brain reading it HAHAH
Stage 2: Figuring out what to do
After spending quite some time reverse-engineering(basically just screwing around), I figured out that the project actually has two GitHub page, one for developing the project itself and one for guiding you to install the production version. Basically, we would need to build the images from the main Github page and link those images to the docker-compose in the production GitHub.
However, this isn’t as simple as some projects like Project-Lightspeed where you could just point docker to the image build directory and call it day. In the case of this project, there is actually a make script that builds the image.
Before we proceed, I would like to reiterate something again, IN NO WAY SHAPE OR FORM IS THIS POST A GUIDE THAT YOU SHOULD BE TRUSTING TO MAKE A PRODUCTION ENVIRONMENT. I DO NOT KNOW WHAT I AM DOING AT ALL AND YOU SHOULD ALWAYS USE THIS AS A MERE REFERENCE. ALWAYS, I REPEAT, ALWAYS REFER BACK TO THE INSTRUCTIONS. RTFM PEOPLE.
https://github.com/debiki/talkyard/blob/release/docs/starting-talkyard.md
Stage 3: Preparing all the prerequisites.
We will need docker and docker-compose; I hope you have that already installed, else you could just follow the gabilions tutorials on installing docker and docker-compose.
Once you settled those, you need to add these to your system. What does it do? No clue, this is what the developer said to do, but looks to have something to do with the search framework it is using, ElasticSearch. After that, reload your system config.
sudo tee -a /etc/sysctl.conf <<EOF
###################################################################
# Talkyard settings
# Up the max backlog queue size (num connections per port), default = 128
net.core.somaxconn=8192
# ElasticSearch requires (at least) this, default = 65530
# Docs: https://www.kernel.org/doc/Documentation/sysctl/vm.txt
vm.max_map_count=262144
# VSCode and IntelliJ Idea want to watch many files — without this, there'll be
# a "Unable to watch for file changes in this large workspace" error in VSCode.
# Also an "User limit of inotify watches reached" error can happen, when
# tailing logs, if too few watches. (The default is sometimes only 8192.)
fs.inotify.max_user_watches=524288
EOFsudo sysctl --system
# you should expect to see these lines once u run this command
* Applying /etc/sysctl.d/99-sysctl.conf ...
net.core.somaxconn = 8192
vm.max_map_count = 262144
fs.inotify.max_user_watches = 524288
* Applying /etc/sysctl.conf ...
net.core.somaxconn = 8192
vm.max_map_count = 262144
fs.inotify.max_user_watches = 524288After that, let’s install all the tools we’ll need to compile the image. I’ve just copy-pasted the install commands from the GitHub, but I’ve added npm in the apt install command.
sudo apt install git make curl jq gpg gnupg2 inotify-tools npm unzip
sh <(curl -L https://nixos.org/nix/install) --no-daemon
sudo npm install yarn
sudo yarn add tslint typescript
sudo npm install n
sudo n stableOnce that’s done, we will begin by creating a folder for this project. And in this folder, we will clone both the development git and production git. I’ll be using the release branch for this guide. Do note that the “git submodule update –innit” command is very important! It downloads the other modules that are linked to this project and these modules are not initialised during the git command. Don’t make a newbie mistake like me!
cd ~
mkdir talkyard
cd talkyard/
git clone -b release https://github.com/debiki/talkyard.git talkyard-dev
cd talkyard-dev
git submodule update --init
cd ..
git clone https://github.com/debiki/talkyard-prod-one.git talkyard-prod
cd talkyard-prod/
git submodule update --init
cd ..
lsWe’re gonna have two folders now, aptly named talkyard-dev and talkyard-prod.
Stage 4: Running the development script
Now, we’re gonna enter the development folder and now try to start up Talkyard. I mean I know it wouldn’t work but let’s try it anyways.
cd talkyard-dev
s/tyd upAnd… here’s our first error
Step 4/14 : RUN apk add --no-cache --repository http://dl-cdn.alpinelinux.org/alpine/edge/testing/ gosu
---> Running in 681759b7e331
fetch http://dl-cdn.alpinelinux.org/alpine/edge/testing/aarch64/APKINDEX.tar.gz
fetch http://dl-cdn.alpinelinux.org/alpine/v3.9/main/aarch64/APKINDEX.tar.gz
WARNING: Ignoring http://dl-cdn.alpinelinux.org/alpine/edge/testing/aarch64/APKINDEX.tar.gz: UNTRUSTED signature
fetch http://dl-cdn.alpinelinux.org/alpine/v3.9/community/aarch64/APKINDEX.tar.gz
ERROR: unsatisfiable constraints:
gosu (missing):
required by: world[gosu]
The command '/bin/sh -c apk add --no-cache --repository http://dl-cdn.alpinelinux.org/alpine/edge/testing/ gosu' returned a non-zero code: 1
ERROR: Service 'app' failed to build : Build failedIt seems that apk(Apline Package Keeper) couldn’t find gosu and therefore the install failed. However, if we look closer at the errors, specifically line 5, it seems to have ignored one of the repositories, seemingly due to “untrusted signature”. This is actually a fairly recent problem because, as it turns out, Alpine Linux had recently changed their key and that resulted in a mismatch of signatures. After some googling, it seems the solution would be to update to a later version of alpine linux. To do that, we have to do some digging in the Dockerfile.
From the docker-compose file, here’s where the Dockerfile is located at.
nano images/app/Dockerfile.devWe can see that the base image for ‘app’ is ‘openjdk:8u212-jdk-alpine3.9’, its basically Alpine Linux 3.9 with Java 8. Typically the first thing I’d do is to find an updated image for it. However, I looked around Docker Hub and couldn’t find a drop in replacement for it. Not only that, the problem doesn’t end there, the image is not only old, but it also doesn’t have an ARM native image. So regardless of the signature issue, it still wouldn’t compile anyways. At this point, the easiest solution is to rebuild this image with just an Alpine Linux image(which does have a ARM version!) and install Java 8 manually. (I’ve tried newer versions of Java LTS, 11 and 13, and it just doesn’t work)
Here’s a list of changes we need to make,
---- FROM openjdk:8u212-jdk-alpine3.9 ++++ FROM alpine:edge ++++ RUN apk add openjdk8
Now let’s try and build the image again… and nope.
/bin/sh: cd: line 0: can't cd to /jre/lib/security: No such file or directory
The command '/bin/sh -c cd $JAVA_HOME/jre/lib/security && keytool -keystore cacerts -storepass changeit -noprompt -trustcacerts -importcert -alias ldapcert -file /smtp-server.crt' returned a non-zero code: 2
ERROR: Service 'app' failed to build : Build failedWell, atleast the earlier problem has been fixed. This time, it seems like Docker couldn’t find the path for the Java security folder. My best guess is that the previous image had the JAVA_HOME environment already predefined. Not to fret, we can just add it ourselves.
++++ ENV JAVA_HOME=/usr/lib/jvm/java-1.8-openjdk
Here’s a side-by-side comparison of the changes made.
FROM openjdk:8u212-jdk-alpine3.9
RUN apk add --no-cache \
# Required:
# (git needed so can include Git revision in the build,
# and show at http://server/-/build-info.)
curl unzip git \
# For PASETO v2.local tokens, needs XChaCha20Poly1305:
libsodium \
# Nice to have:
tree less wget net-tools bash \
# tput, needed by Coursier somehow
ncurses \
# Telnet, nice for troubleshooting SMTP problems for example.
busybox-extras
# ADD extracts tar archives; this .tgz gets unpacked at /opt/sbt/{bin/,conf/}.
ADD sbt/sbt-1.4.5.tgz /opt/
# Install 'gosu' so we can use it instead of 'su'.
# For unknown reasons, ' exec su ...' no longer works, but 'exec gosu ...' works fine.
RUN apk add --no-cache \
--repository http://dl-cdn.alpinelinux.org/alpine/edge/testing/ \
gosu
# Play's HTTP and HTTPS listen ports, Java debugger port, JMX port 3333.
EXPOSE 9000 9443 9999 3333
RUN mkdir -p /opt/talkyard/uploads/ && \
chmod -R ugo+rw /opt/talkyard/uploads/
# Add a self signed dummy cert for the dummy SMTP server (the 'fakemail' Docker container),
# so one can test connecting to it with TLS and see if the TLS conf vals work. [26UKWD2]
# ("changeit" = default keystore password)
COPY fakemail-publ-test-self-signed.crt /smtp-server.crt
RUN cd $JAVA_HOME/jre/lib/security && \
keytool -keystore cacerts -storepass changeit -noprompt -trustcacerts \
-importcert -alias ldapcert -file /smtp-server.crt
WORKDIR /opt/talkyard/app/
# Don't do until now, so won't need to rebuild whole image if editing entrypoint.
COPY entrypoint.dev.sh /docker-entrypoint.sh
RUN chmod ugo+x /docker-entrypoint.sh
ENTRYPOINT ["/docker-entrypoint.sh"]
# Overriden in docker-compose.yml
ENV PLAY_HEAP_MEMORY_MB 1048FROM alpine:edge
RUN apk add openjdk8
RUN apk add --no-cache \
# Required:
# (git needed so can include Git revision in the build,
# and show at http://server/-/build-info.)
curl unzip git \
# For PASETO v2.local tokens, needs XChaCha20Poly1305:
libsodium \
# Nice to have:
tree less wget net-tools bash \
# tput, needed by Coursier somehow
ncurses \
# Telnet, nice for troubleshooting SMTP problems for example.
busybox-extras
# ADD extracts tar archives; this .tgz gets unpacked at /opt/sbt/{bin/,conf/}.
ADD sbt/sbt-1.4.5.tgz /opt/
# Install 'gosu' so we can use it instead of 'su'.
# For unknown reasons, ' exec su ...' no longer works, but 'exec gosu ...' works fine.
RUN apk add --no-cache \
--repository http://dl-cdn.alpinelinux.org/alpine/edge/testing/ \
gosu
# Play's HTTP and HTTPS listen ports, Java debugger port, JMX port 3333.
EXPOSE 9000 9443 9999 3333
RUN mkdir -p /opt/talkyard/uploads/ && \
chmod -R ugo+rw /opt/talkyard/uploads/
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk
# Add a self signed dummy cert for the dummy SMTP server (the 'fakemail' Docker container),
# so one can test connecting to it with TLS and see if the TLS conf vals work. [26UKWD2]
# ("changeit" = default keystore password)
COPY fakemail-publ-test-self-signed.crt /smtp-server.crt
RUN cd $JAVA_HOME/jre/lib/security && \
keytool -keystore cacerts -storepass changeit -noprompt -trustcacerts \
-importcert -alias ldapcert -file /smtp-server.crt
WORKDIR /opt/talkyard/app/
# Don't do until now, so won't need to rebuild whole image if editing entrypoint.
COPY entrypoint.dev.sh /docker-entrypoint.sh
RUN chmod ugo+x /docker-entrypoint.sh
ENTRYPOINT ["/docker-entrypoint.sh"]
# Overriden in docker-compose.yml
ENV PLAY_HEAP_MEMORY_MB 1048
s/tyd upWell, it seems to have been able to build it just fine it seems! But there’s a new error again, but one that I was expecting from the beginning.
Building fakeweb
Sending build context to Docker daemon 14.34kB
Step 1/9 : FROM denoland/deno:1.20.1
1.20.1: Pulling from denoland/deno
26e7f2019eb6: Pull complete
cc2084920473: Pull complete
4f340e99d696: Pull complete
8c3be2d727f8: Pull complete
04f22b8fc933: Pull complete
280c543a70c4: Pull complete
Digest: sha256:8ccd586578055cc4b84ba9be9ba8719c3c34c2b402f49ee3b25570ff2409599d
Status: Downloaded newer image for denoland/deno:1.20.1
---> 7124456b5e86
Step 2/9 : RUN apt-get update && apt-get install -y tree curl net-tools procps
---> [Warning] The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
---> Running in 0f245fdee2fc
exec /bin/sh: exec format error
The command '/bin/sh -c apt-get update && apt-get install -y tree curl net-tools procps' returned a non-zero code: 1
ERROR: Service 'fakeweb' failed to build : Build failedSeems like when docker is trying to build ‘fakeweb’, it failed because the image is incompatible with ARM. Let’s take a look at the docker file.
nano images/fakeweb/Dockerfile And guess what, the base image it is using, denoland/deno:1.20.1, has no ARM version. Luckily for us, someone has graciously built and uploaded an ARM version of deno.
---- FROM denoland/deno:1.20.1 ++++ FROM lukechannings/deno:v1.20.1
Let’s give this another go.
s/tyd upNow if you let it build again, you might be surprised to see that eventually, everything manages to be built successfully. To test it out, let’s head on over to http://localhost. If it works we should expect a page to run the initial config. But well, it ain’t working. This is what you’ll see on the page.
500 Internal Server Error
Something went wrong: [DwE500EXC]
java.net.UnknownHostException: search: Try again
at java.net.Inet4AddressImpl.lookupAllHostAddr(Native Method)
at java.net.InetAddress$2.lookupAllHostAddr(InetAddress.java:930)
at java.net.InetAddress.getAddressesFromNameService(InetAddress.java:1325)
at java.net.InetAddress.getAllByName0(InetAddress.java:1278)
at java.net.InetAddress.getAllByName(InetAddress.java:1194)
at java.net.InetAddress.getAllByName(InetAddress.java:1128)
at java.net.InetAddress.getByName(InetAddress.java:1078)
at debiki.Globals$State.<init>(Globals.scala:1169)
at debiki.Globals.tryCreateStateUntilKilled(Globals.scala:940)
at debiki.Globals.$anonfun$startStuff$1(Globals.scala:871)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at scala.concurrent.Future$.$anonfun$apply$1(Future.scala:659)
at scala.util.Success.$anonfun$map$1(Try.scala:255)
at scala.util.Success.map(Try.scala:213)
at scala.concurrent.Future.$anonfun$map$1(Future.scala:292)
at scala.concurrent.impl.Promise.liftedTree1$1(Promise.scala:33)
at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:33)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)
at akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.scala:63)
at akka.dispatch.BatchingExecutor$BlockableBatch.$anonfun$run$1(BatchingExecutor.scala:100)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:85)
at akka.dispatch.BatchingExecutor$BlockableBatch.run(BatchingExecutor.scala:100)
at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:49)
at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(ForkJoinExecutorConfigurator.scala:48)
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:175)
Soon after, you’ll also start seeing this error page. This is because the ‘app’ image keeps crashing(due to the error) and restarts itself. However, it doesn’t close its previous connections to the database and eventually, it exceeds the maximum connection limit. As such, the database will start rejecting any new connection attempts, causing the ‘app’ to fail to talk to the database.
500 Internal Server Error
Talkyard's application server is trying to start, but cannot connect to the PostgreSQL database server [TyEDATABCONN1]
Has the database stopped or is there a network problem?
See if the database container is running — it's name is something like 'tyd_rdb_X':
docker-compose ps
If not running, start it:
docker-compose start rdb
If running, check the logs:
docker-compose logs -f --tail 999 app rdb
Or login with Bash:
docker-compose exec rdb bash
debiki.Globals$DatabasePoolInitializationException: com.zaxxer.hikari.pool.HikariPool$PoolInitializationException: Failed to initialize pool: FATAL: remaining connection slots are reserved for non-replication superuser connections
at debiki.Globals.tryCreateStateUntilKilled(Globals.scala:952)
at debiki.Globals.$anonfun$startStuff$1(Globals.scala:871)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at scala.concurrent.Future$.$anonfun$apply$1(Future.scala:659)
at scala.util.Success.$anonfun$map$1(Try.scala:255)
at scala.util.Success.map(Try.scala:213)
at scala.concurrent.Future.$anonfun$map$1(Future.scala:292)
at scala.concurrent.impl.Promise.liftedTree1$1(Promise.scala:33)
at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:33)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)
at akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.scala:63)
at akka.dispatch.BatchingExecutor$BlockableBatch.$anonfun$run$1(BatchingExecutor.scala:100)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:85)
at akka.dispatch.BatchingExecutor$BlockableBatch.run(BatchingExecutor.scala:100)
at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:49)
at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(ForkJoinExecutorConfigurator.scala:48)
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:175)
Caused by: com.zaxxer.hikari.pool.HikariPool$PoolInitializationException: Failed to initialize pool: FATAL: remaining connection slots are reserved for non-replication superuser connections
at com.zaxxer.hikari.pool.HikariPool.throwPoolInitializationException(HikariPool.java:596)
at com.zaxxer.hikari.pool.HikariPool.checkFailFast(HikariPool.java:582)
at com.zaxxer.hikari.pool.HikariPool.<init>(HikariPool.java:115)
at com.zaxxer.hikari.HikariDataSource.<init>(HikariDataSource.java:81)
at debiki.Debiki$.createPostgresHikariDataSource(Debiki.scala:129)
at debiki.Globals.tryCreateStateUntilKilled(Globals.scala:928)
... 20 more
Caused by: org.postgresql.util.PSQLException: FATAL: remaining connection slots are reserved for non-replication superuser connections
at org.postgresql.Driver$ConnectThread.getResult(Driver.java:353)
at org.postgresql.Driver.connect(Driver.java:268)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:247)
at org.postgresql.ds.common.BaseDataSource.getConnection(BaseDataSource.java:103)
at com.zaxxer.hikari.pool.PoolBase.newConnection(PoolBase.java:364)
at com.zaxxer.hikari.pool.PoolBase.newPoolEntry(PoolBase.java:206)
at com.zaxxer.hikari.pool.HikariPool.createPoolEntry(HikariPool.java:476)
at com.zaxxer.hikari.pool.HikariPool.checkFailFast(HikariPool.java:561)
... 24 moreAnyways before we start fixing anything, let’s shut everything down. Ctrl + C to abort.
s/tyd downSo at this point, you’ll be like, “So what’s wrong now? Everything has been built successfully right?” Well, actually it didn’t! If you actually looked closely at all out the console output when the image was being built, you’d notice something’s off. The first error page actually gives us a hint, line 5, the keyword being “search”
Building search
Sending build context to Docker daemon 13.31kB
Step 1/6 : FROM docker.elastic.co/elasticsearch/elasticsearch-oss:6.8.23
6.8.23: Pulling from elasticsearch/elasticsearch-oss
a4f595742a5b: Pull complete
22655d42aa4e: Pull complete
27706986c7b4: Pull complete
c8a817575371: Pull complete
9e8232452606: Pull complete
5f0f4c9445d6: Pull complete
09baf057135d: Pull complete
Digest: sha256:740c3614289539e9782b8a3c4de5100599bbec669d6c56bc21a76eea661e80a5
Status: Downloaded newer image for docker.elastic.co/elasticsearch/elasticsearch-oss:6.8.23
---> c1a1ae448835
Step 2/6 : COPY elasticsearch.yml log4j2.properties /usr/share/elasticsearch/config/
---> 2747be973cb6
Step 3/6 : USER root
---> [Warning] The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
---> Running in d6ac169ba091
Removing intermediate container d6ac169ba091
---> 3bd4cc89a83e
Step 4/6 : COPY entrypoint.sh /docker-entrypoint.sh
---> e7b30ccda035
Step 5/6 : ENTRYPOINT ["/docker-entrypoint.sh"]
---> [Warning] The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
---> Running in 96d8e773efcf
Removing intermediate container 96d8e773efcf
---> 6208f25221af
Step 6/6 : CMD /usr/share/elasticsearch/bin/elasticsearch
---> [Warning] The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
---> Running in f02e30b9e545
Removing intermediate container f02e30b9e545
---> 4ddc38263ffe
Successfully built 4ddc38263ffe
Successfully tagged debiki/talkyard-search:latestIf we scroll up, we’ll see this chunk of console output. Lines 18, 25, and 30 are key, telling us that docker failed to pull an image due to a lack of an ARM native version. Long story short, we need to fix ‘search’.
nano images/search/DockerfileAt this point, I think you know what we’re doing already. If we have a look at the repository of elasticsearch, it does seem that the later version of the docker images does have an ARM native version, but it’s only for later versions of elasticsearch. This is a problem but I’ll touch on it later on.
---- FROM docker.elastic.co/elasticsearch/elasticsearch-oss:6.8.23 ++++ FROM docker.elastic.co/elasticsearch/elasticsearch-oss:7.10.2
Once you’ve made the changes, we need to tell docker-compose to rebuild all the images. This step is required as the faulty version of the image was “successfully” built. So even if we modified the Dockerfile, docker-compose would not rebuild the image.
docker-compose build
s/tyd upSeems like we’re making progress! We can see output from the search, but something seems wrong again. Huh, still this error at localhost.
500 Internal Server Error
Something went wrong: [DwE500EXC]
java.net.UnknownHostException: search: Try again
at java.net.Inet4AddressImpl.lookupAllHostAddr(Native Method)
at java.net.InetAddress$2.lookupAllHostAddr(InetAddress.java:930)
at java.net.InetAddress.getAddressesFromNameService(InetAddress.java:1331)
at java.net.InetAddress.getAllByName0(InetAddress.java:1284)
at java.net.InetAddress.getAllByName(InetAddress.java:1200)
at java.net.InetAddress.getAllByName(InetAddress.java:1128)
at java.net.InetAddress.getByName(InetAddress.java:1078)
at debiki.Globals$State.<init>(Globals.scala:1169)
at debiki.Globals.tryCreateStateUntilKilled(Globals.scala:940)
at debiki.Globals.$anonfun$startStuff$1(Globals.scala:871)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at scala.concurrent.Future$.$anonfun$apply$1(Future.scala:659)
at scala.util.Success.$anonfun$map$1(Try.scala:255)
at scala.util.Success.map(Try.scala:213)
at scala.concurrent.Future.$anonfun$map$1(Future.scala:292)
at scala.concurrent.impl.Promise.liftedTree1$1(Promise.scala:33)
at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:33)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)
at akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.scala:63)
at akka.dispatch.BatchingExecutor$BlockableBatch.$anonfun$run$1(BatchingExecutor.scala:100)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:85)
at akka.dispatch.BatchingExecutor$BlockableBatch.run(BatchingExecutor.scala:100)
at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:49)
at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(ForkJoinExecutorConfigurator.scala:48)
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:175)Let’s exit(Ctrl+C) and take a look at the logs for search.
docker logs talkyard-search_1[1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
ERROR: Elasticsearch did not exit normally - check the logs at /usr/share/elasticsearch/logs/elasticsearch.logHere’s the problem. Basically in Elasticsearch 7.x.x, there have been some changes in the discovery settings. We need to modify the config files to add an important line.
s/tyd down
nano images/search/elasticsearch.yml++++ discovery.type: single-node
Now we need to rebuild the search image again.
docker-compose build
s/tyd upAnd et voilà! There’s the mythical set up page!
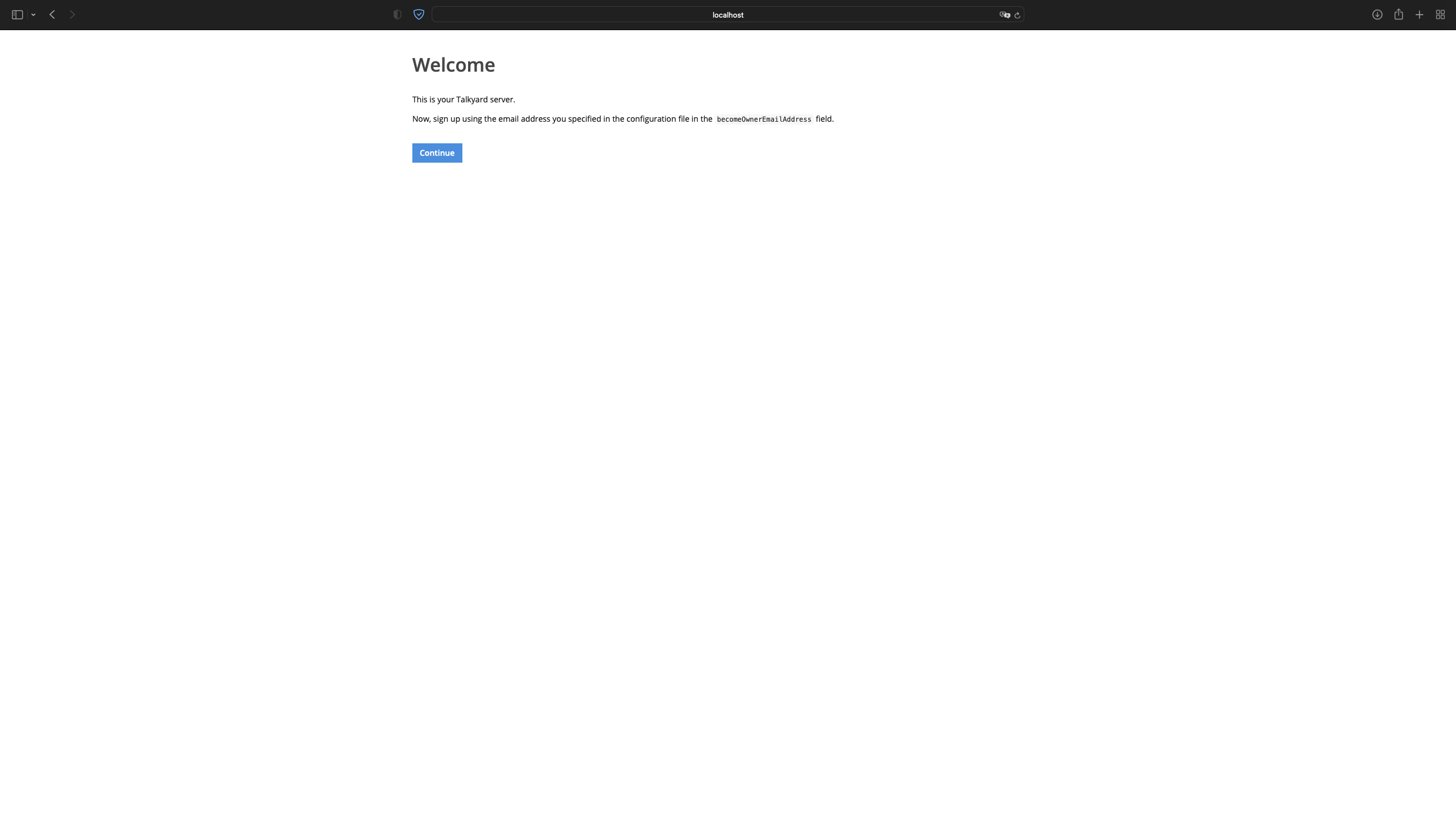
Anyways, lets have a look at the docker-compose.yml. At this point, its also a good idea to just go through every container compose is trying to build and check if any of the images need to be swapped for an ARM equivalent. After checking all of the images, it seems like we need to change element-web,
Actually, this is no longer needed as the developer for element-web started releasing images for ARM as well. Previously we’d have to also build the image ourselves from the source code, but thankfully it was fairly simple. I’m leaving that paragraph in as sort of a reminder for myself lol.
To polish some stuff
Now, while we might’ve gotten to the setup page, and things generally do work, but I’m sure you’ve seen the plethora of error messages in the console.
search_1 | [2022-08-25T16:45:57,944][INFO ][o.e.c.m.MetadataCreateIndexService] [9d267d61115b] failed on parsing mappings on index creation [all_english_v1]
search_1 | org.elasticsearch.index.mapper.MapperParsingException: Failed to parse mapping [post]: Root mapping definition has unsupported parameters: [_all : {enabled=false}]
search_1 | at org.elasticsearch.index.mapper.MapperService.internalMerge(MapperService.java:417) ~[elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.index.mapper.MapperService.merge(MapperService.java:353) ~[elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.updateIndexMappingsAndBuildSortOrder(MetadataCreateIndexService.java:977) ~[elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.lambda$applyCreateIndexWithTemporaryService$3(MetadataCreateIndexService.java:409) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.indices.IndicesService.withTempIndexService(IndicesService.java:619) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.applyCreateIndexWithTemporaryService(MetadataCreateIndexService.java:407) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.applyCreateIndexRequestWithV1Templates(MetadataCreateIndexService.java:494) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.applyCreateIndexRequest(MetadataCreateIndexService.java:370) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.applyCreateIndexRequest(MetadataCreateIndexService.java:377) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService$1.execute(MetadataCreateIndexService.java:300) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.ClusterStateUpdateTask.execute(ClusterStateUpdateTask.java:47) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.service.MasterService.executeTasks(MasterService.java:702) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.service.MasterService.calculateTaskOutputs(MasterService.java:324) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.service.MasterService.runTasks(MasterService.java:219) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.service.MasterService.access$000(MasterService.java:73) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.service.MasterService$Batcher.run(MasterService.java:151) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.service.TaskBatcher.runIfNotProcessed(TaskBatcher.java:150) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.cluster.service.TaskBatcher$BatchedTask.run(TaskBatcher.java:188) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:684) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.runAndClean(PrioritizedEsThreadPoolExecutor.java:252) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.run(PrioritizedEsThreadPoolExecutor.java:215) [elasticsearch-7.10.2.jar:7.10.2]
search_1 | at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130) [?:?]
search_1 | at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630) [?:?]
search_1 | at java.lang.Thread.run(Thread.java:832) [?:?]
search_1 | Caused by: org.elasticsearch.index.mapper.MapperParsingException: Root mapping definition has unsupported parameters: [_all : {enabled=false}]
search_1 | at org.elasticsearch.index.mapper.DocumentMapperParser.checkNoRemainingFields(DocumentMapperParser.java:158) ~[elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.index.mapper.DocumentMapperParser.parse(DocumentMapperParser.java:146) ~[elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.index.mapper.DocumentMapperParser.parse(DocumentMapperParser.java:98) ~[elasticsearch-7.10.2.jar:7.10.2]
search_1 | at org.elasticsearch.index.mapper.MapperService.internalMerge(MapperService.java:415) ~[elasticsearch-7.10.2.jar:7.10.2]
search_1 | ... 23 moreapp_1 | 16:45:52.962 [error] t.IndexCreator Error creating search index for 'english' [EsE8BF5]
app_1 | org.elasticsearch.index.mapper.MapperParsingException: Failed to parse mapping [post]: Root mapping definition has unsupported parameters: [_all : {enabled=false}]
app_1 | at org.elasticsearch.index.mapper.MapperService.internalMerge(MapperService.java:417)
app_1 | at org.elasticsearch.index.mapper.MapperService.merge(MapperService.java:353)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.updateIndexMappingsAndBuildSortOrder(MetadataCreateIndexService.java:977)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.lambda$applyCreateIndexWithTemporaryService$3(MetadataCreateIndexService.java:409)
app_1 | at org.elasticsearch.indices.IndicesService.withTempIndexService(IndicesService.java:619)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.applyCreateIndexWithTemporaryService(MetadataCreateIndexService.java:407)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.applyCreateIndexRequestWithV1Templates(MetadataCreateIndexService.java:494)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.applyCreateIndexRequest(MetadataCreateIndexService.java:370)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.applyCreateIndexRequest(MetadataCreateIndexService.java:377)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService$1.execute(MetadataCreateIndexService.java:300)
app_1 | at org.elasticsearch.cluster.ClusterStateUpdateTask.execute(ClusterStateUpdateTask.java:47)
app_1 | at org.elasticsearch.cluster.service.MasterService.executeTasks(MasterService.java:702)
app_1 | at org.elasticsearch.cluster.service.MasterService.calculateTaskOutputs(MasterService.java:324)
app_1 | at org.elasticsearch.cluster.service.MasterService.runTasks(MasterService.java:219)
app_1 | at org.elasticsearch.cluster.service.MasterService.access$000(MasterService.java:73)
app_1 | at org.elasticsearch.cluster.service.MasterService$Batcher.run(MasterService.java:151)
app_1 | at org.elasticsearch.cluster.service.TaskBatcher.runIfNotProcessed(TaskBatcher.java:150)
app_1 | at org.elasticsearch.cluster.service.TaskBatcher$BatchedTask.run(TaskBatcher.java:188)
app_1 | at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:684)
app_1 | at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.runAndClean(PrioritizedEsThreadPoolExecutor.java:252)
app_1 | at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.run(PrioritizedEsThreadPoolExecutor.java:215)
app_1 | at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130)
app_1 | at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630)
app_1 | at java.lang.Thread.run(Thread.java:832)
app_1 | Caused by: org.elasticsearch.index.mapper.MapperParsingException: Root mapping definition has unsupported parameters: [_all : {enabled=false}]
app_1 | at org.elasticsearch.index.mapper.DocumentMapperParser.checkNoRemainingFields(DocumentMapperParser.java:158)
app_1 | at org.elasticsearch.index.mapper.DocumentMapperParser.parse(DocumentMapperParser.java:146)
app_1 | at org.elasticsearch.index.mapper.DocumentMapperParser.parse(DocumentMapperParser.java:98)
app_1 | at org.elasticsearch.index.mapper.MapperService.internalMerge(MapperService.java:415)
app_1 | ... 23 common frames omitted
app_1 | 16:45:52.963 [error] t.IndexActor Error in actor IndexActor when handling IndexStuff$ [TyEJANTHR]
app_1 | org.elasticsearch.index.mapper.MapperParsingException: Failed to parse mapping [post]: Root mapping definition has unsupported parameters: [_all : {enabled=false}]
app_1 | at org.elasticsearch.index.mapper.MapperService.internalMerge(MapperService.java:417)
app_1 | at org.elasticsearch.index.mapper.MapperService.merge(MapperService.java:353)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.updateIndexMappingsAndBuildSortOrder(MetadataCreateIndexService.java:977)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.lambda$applyCreateIndexWithTemporaryService$3(MetadataCreateIndexService.java:409)
app_1 | at org.elasticsearch.indices.IndicesService.withTempIndexService(IndicesService.java:619)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.applyCreateIndexWithTemporaryService(MetadataCreateIndexService.java:407)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.applyCreateIndexRequestWithV1Templates(MetadataCreateIndexService.java:494)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.applyCreateIndexRequest(MetadataCreateIndexService.java:370)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService.applyCreateIndexRequest(MetadataCreateIndexService.java:377)
app_1 | at org.elasticsearch.cluster.metadata.MetadataCreateIndexService$1.execute(MetadataCreateIndexService.java:300)
app_1 | at org.elasticsearch.cluster.ClusterStateUpdateTask.execute(ClusterStateUpdateTask.java:47)
app_1 | at org.elasticsearch.cluster.service.MasterService.executeTasks(MasterService.java:702)
app_1 | at org.elasticsearch.cluster.service.MasterService.calculateTaskOutputs(MasterService.java:324)
app_1 | at org.elasticsearch.cluster.service.MasterService.runTasks(MasterService.java:219)
app_1 | at org.elasticsearch.cluster.service.MasterService.access$000(MasterService.java:73)
app_1 | at org.elasticsearch.cluster.service.MasterService$Batcher.run(MasterService.java:151)
app_1 | at org.elasticsearch.cluster.service.TaskBatcher.runIfNotProcessed(TaskBatcher.java:150)
app_1 | at org.elasticsearch.cluster.service.TaskBatcher$BatchedTask.run(TaskBatcher.java:188)
app_1 | at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:684)
app_1 | at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.runAndClean(PrioritizedEsThreadPoolExecutor.java:252)
app_1 | at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.run(PrioritizedEsThreadPoolExecutor.java:215)
app_1 | at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130)
app_1 | at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630)
app_1 | at java.lang.Thread.run(Thread.java:832)
app_1 | Caused by: org.elasticsearch.index.mapper.MapperParsingException: Root mapping definition has unsupported parameters: [_all : {enabled=false}]
app_1 | at org.elasticsearch.index.mapper.DocumentMapperParser.checkNoRemainingFields(DocumentMapperParser.java:158)
app_1 | at org.elasticsearch.index.mapper.DocumentMapperParser.parse(DocumentMapperParser.java:146)
app_1 | at org.elasticsearch.index.mapper.DocumentMapperParser.parse(DocumentMapperParser.java:98)
app_1 | at org.elasticsearch.index.mapper.MapperService.internalMerge(MapperService.java:415)
app_1 | ... 23 common frames omitted
ty-it-mx-synapse_1 | Starting synapse with args -m synapse.app.homeserver --config-path /data/homeserver.yaml
ty-it-mx-synapse_1 | Traceback (most recent call last):
ty-it-mx-synapse_1 | File "/usr/local/lib/python3.9/runpy.py", line 197, in _run_module_as_main
ty-it-mx-synapse_1 | return _run_code(code, main_globals, None,
ty-it-mx-synapse_1 | File "/usr/local/lib/python3.9/runpy.py", line 87, in _run_code
ty-it-mx-synapse_1 | exec(code, run_globals)
ty-it-mx-synapse_1 | File "/usr/local/lib/python3.9/site-packages/synapse/app/homeserver.py", line 426, in <module>
ty-it-mx-synapse_1 | main()
ty-it-mx-synapse_1 | File "/usr/local/lib/python3.9/site-packages/synapse/app/homeserver.py", line 416, in main
ty-it-mx-synapse_1 | hs = setup(sys.argv[1:])
ty-it-mx-synapse_1 | File "/usr/local/lib/python3.9/site-packages/synapse/app/homeserver.py", line 324, in setup
ty-it-mx-synapse_1 | config = HomeServerConfig.load_or_generate_config(
ty-it-mx-synapse_1 | File "/usr/local/lib/python3.9/site-packages/synapse/config/_base.py", line 742, in load_or_generate_config
ty-it-mx-synapse_1 | obj.parse_config_dict(
ty-it-mx-synapse_1 | File "/usr/local/lib/python3.9/site-packages/synapse/config/_base.py", line 763, in parse_config_dict
ty-it-mx-synapse_1 | self.invoke_all(
ty-it-mx-synapse_1 | File "/usr/local/lib/python3.9/site-packages/synapse/config/_base.py", line 392, in invoke_all
ty-it-mx-synapse_1 | res[config_class.section] = getattr(config, func_name)(*args, **kwargs)
ty-it-mx-synapse_1 | File "/usr/local/lib/python3.9/site-packages/synapse/config/repository.py", line 141, in read_config
ty-it-mx-synapse_1 | self.media_store_path = self.ensure_directory(
ty-it-mx-synapse_1 | File "/usr/local/lib/python3.9/site-packages/synapse/config/_base.py", line 241, in ensure_directory
ty-it-mx-synapse_1 | os.makedirs(dir_path, exist_ok=True)
ty-it-mx-synapse_1 | File "/usr/local/lib/python3.9/os.py", line 225, in makedirs
ty-it-mx-synapse_1 | mkdir(name, mode)
ty-it-mx-synapse_1 | PermissionError: [Errno 13] Permission denied: '/data/media_store'
tyd_ty-it-mx-synapse_1 exited with code 1Problem with MX-Synapse
The problem with mx-synapse seems to be a fairly simple one, just some permissions error. If we take a look at the docker-compose file
nano docker-compose.ymlty-it-mx-synapse:
image: matrixdotorg/synapse:latest
# matrixdotorg/synapse:v1.53.0
# see: https://hub.docker.com/r/matrixdotorg/synapse/tags
restart: unless-stopped
volumes:
- ./volumes/matrix-synapse-data:/data
- ./tests/int-w/matrix/homeserver.yaml:/data/homeserver.yaml
networks:
internal_net:
ipv4_address: ${INTERNAL_NET_MX_SYNAPSE_IP}
ports:
- '8008:8008' # connections from end user clients, to send messages
- '8009:8009' # This is a Websocket proxy, which turns the ws messages
# into HTTP requests to port :8008?
# See: https://github.com/matrix-org/matrix-websockets-proxy/blob/master/main.go
# '8448:8448' # connections from other servers, for federation
#default:
#ipv4_address: 10.10.10.4From line 7, it seems that the folder /volumes/matrix-synapse-data that docker mounts as /data in the containers has some permissions issue. Since docker preserves the original folder permissions from the host, we need to fix the permissions issue in the talkyard-dev folder.
sudo chmod -R 777 volumes/matrix-synapse-data/
s/tyd upSeems like a new error has popped up. Well, this is the part where I actually tell you I haven’t been able to figure it out, but at the same time, mx-synapse doesn’t really matter for the production build of talk yard so I’ll just move on for now.
Error in configuration at 'signing_key':
ty-it-mx-synapse_1 | Error accessing file '/data/ty-it-mx-synapse.localhost.signing.key':
ty-it-mx-synapse_1 | [Errno 2] No such file or directory: '/data/ty-it-mx-synapse.localhost.signing.key'Regarding Search
Now, this is another tough one. By the looks of it, Elasticsearch v7.x.x introduced depreciated some stuff that Talkyard uses. And it would be a huge undertaking to try and fix whatever old code that needs changing. The more logical thing to do would be to rebuild Elasticsearch:6.8.23, which I will get into it later on after building the production builds.
Stage 5: Moving onto production builds
NOTE! ANYTHING BEYOND THIS IS STILL A WORK IN PROGRESS!!!
Here comes the most important stage for this experiment, to actually deploy a production build.
And before we actually start the build, we should also tag the version and the repository that we plan to use. For me, I’ll be building the images with my repository and I will push them to Docker Hub.
nano version.txtFor me, the naming convention I’m using is just the year.month, for eg. v2022.09. Now to change the name of the repository.
nano .env---- DOCKER_REPOSITORY=debiki ++++ DOCKER_REPOSITORY=leejacksonz
Remember we had to make some changes for the app? As in the image ‘app’. What we modified last time was the development Dockerfile, now we gotta make the same changes in the production Dockerfile.
nano images/app/Dockerfile.dev---- FROM openjdk:8u212-jdk-alpine3.9 ++++ FROM alpine:edge ++++ RUN apk add openjdk8 ++++ ENV JAVA_HOME=/usr/lib/jvm/java-1.8-openjdk
Now we’re ready to build the production images. There is a new command we are going to use. But, before we do that, I like to do some precautionary steps and make sure all the containers, images, and volumes are removed.
s/tyd down
docker system prune -a
docker volumes prune -f
make prod-imagesAfter executing that command, you’ll most likely be stuck at this stage.
sudo docker-compose -pedt kill web app search cache rdb ;\
sudo docker-compose -pedt down
Removing network edt_internal_net
WARNING: Network edt_internal_net not found.
Removing network edt_default
WARNING: Network edt_default not found.
s/build-prod-images.sh
Do in another shell: (so I can run end-to-end tests)
d/selenium
Waiting for you ...
.......................What we need to do now is to open another terminal and run the d/selenium script.
~/talkyard/talkyard-dev/d/seleniumYou can say no to the Vinagre. However, we see this dreaded message again.
WARNING: The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requestedWell, let’s just terminate(Ctrl+X). For this, we need to investigate the script.
nano d/selenium#!/bin/bash
# See ../s/selenium-start for how to debug.
# Git repo & docs: https://github.com/SeleniumHQ/docker-selenium
#
dash_debug="-debug"
browser_name="chrome"
container_name="tye2ebrowser"
# !! Update Chromedriver and FF driver in wdio.conf.ts too. [upd_chromedriver_ffdriver]
# Not using — see image_name below instead.
image_version="4.0.0-alpha-7-prerelease-20201009" # 3.141.59-20201010"
#image_version="selenium/standalone-chrome:4.0.0-beta-4-prerelease-20210527"
# Is 3.5.x and 4.0.0 Selenium Grid? Selenium Server? versions?
# https://www.selenium.dev/downloads/
# It's "Selenium" version:
# https://selenium-release.storage.googleapis.com/index.html
# not the same as: selenium/standalone-chrome:86.0-20201009 — then would need
# Chromedriver too in another Docker container?
# This one?: selenium/standalone-chrome:86.0-chromedriver-86.0-20201009
# A common 14'' laptop resolution is 1920x1200, so this should work
# both on wide screens and not-too-small-screen laptops:
WIDTH=1850
HEIGHT=1100
The problem here is that ‘make prod-images’ is using selenium to test the images. However, the selenium image is brought up through docker, and the image that is being pulled is not ARM compatible. Time to fix that and try again.
---- image_version="4.0.0-alpha-7-prerelease-20201009" # 3.141.59-20201010"
++++ image_version="4.0.0-20211111" # 3.141.59-20201010"
---- image_name="selenium/standalone-chrome:4.0.0-alpha-7-prerelease-20201009"
++++ image_name="seleniarm/standalone-chromium:4.0.0-20211111"
~/talkyard/talkyard-dev/d/selenium
make prod-imagesOkay! Now it’s running!
yarn run v1.22.19
$ npm run build-ts && npm run tslint
npm WARN lifecycle The node binary used for scripts is /run/user/1000/yarn--1661449149284-0.34500863803012605/node but npm is using /nix/store/04qa0m42kmn96ddxzfly0cj8hr5a87f9-nodejs-14.20.0/bin/node itself. Use the `--scripts-prepend-node-path` option to include the path for the node binary npm was executed with.
> [email protected] build-ts /home/jack/talkyard2/talkyard-dev/to-talkyard
> tsc
sh: line 1: tsc: command not found
npm ERR! code ELIFECYCLE
npm ERR! syscall spawn
npm ERR! file sh
npm ERR! errno ENOENT
npm ERR! [email protected] build-ts: `tsc`
npm ERR! spawn ENOENT
npm ERR!
npm ERR! Failed at the [email protected] build-ts script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
npm WARN Local package.json exists, but node_modules missing, did you mean to install?
npm ERR! A complete log of this run can be found in:
npm ERR! /home/jack/.npm/_logs/2022-08-25T17_39_09_438Z-debug.log
error Command failed with exit code 1.
info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.
make: *** [Makefile:609: prod-images] Error 1
Hmm, another error, line 8, tsc not found.
After a bit, you’ll come across this error, but luckily it tells you how to fix it.
src/from-disqus-to-ty.ts:8:22 - error TS7016: Could not find a declaration file for module 'sax'. '/home/jack/talkyard/talkyard-dev/node_modules/sax/lib/sax.js' implicitly has an 'any' type.
Try `npm i --save-dev @types/sax` if it exists or add a new declaration (.d.ts) file containing `declare module 'sax';`
8 import * as sax from 'sax';
~~~~~
src/from-wordpress-to-ty.ts:5:22 - error TS7016: Could not find a declaration file for module 'sax'. '/home/jack/talkyard/talkyard-dev/node_modules/sax/lib/sax.js' implicitly has an 'any' type.
Try `npm i --save-dev @types/sax` if it exists or add a new declaration (.d.ts) file containing `declare module 'sax';`
5 import * as sax from 'sax';
~~~~~sudo npm i --save-dev @types/sax
make prod-imagesLater on, you’re gonna face another problem, which is at line 13.
Running Webdrier.io E2E tests ...
This script, run-e2e-tests.sh is DEPRECATED, but still in use.
Soon, will use instead: s/tyd e2e ...
Waiting for Nashorn to compile Javascript code... (polling http://localhost/-/are-scripts-ready )
............Running all end-to-end tests...
————————————————————————————————————————————————————————————————————
Next test: s/wdio --only manual.2browsers --prod --deleteOldSite --localHostname=e2e-test-e1-o0-s1 --dummy-wdio-test 2022-08-26T10:22:45+08:00-be1jxe646s
NODE_TLS_REJECT_UNAUTHORIZED=0 node_modules/.bin/wdio wdio.conf.js --only manual.2browsers --prod --deleteOldSite --localHostname=e2e-test-e1-o0-s1 --dummy-wdio-test 2022-08-26T10:22:45+08:00-be1jxe646s
s/wdio: line 12: node_modules/.bin/wdio: No such file or directory
Error. E2E test failed, exit code: 127
Was started like so:
NODE_TLS_REJECT_UNAUTHORIZED=0 node_modules/.bin/wdio wdio.conf.js --only manual.2browsers --prod --deleteOldSite --localHostname=e2e-test-e1-o0-s1 --dummy-wdio-test 2022-08-26T10:22:45+08:00-be1jxe646s
Log file: logs/failed-e2e-test-2022-08-26T10:22:45+08:00-be1jxe646s-nr-1.log
*** Test failed 1/3. Waiting a few seconds, then will retry ... [EdME2ETRY1] ***sudo npm i --save-dev @wdio/cli
npm init wdio . --unsafe-perm? Where is your automation backend located? I have my own Selenium cloud
? What is the IP or URI to your Selenium standalone or grid server? localhost
? What is the port which your Selenium standalone or grid server is running on? 4444
? What is the path to your browser driver or grid server? /
? Which framework do you want to use? mocha
? Do you want to use a compiler? No!
? Where are your test specs located? ./test/specs/**/*.js
? Do you want WebdriverIO to autogenerate some test files? Yes
? Do you want to use page objects (https://martinfowler.com/bliki/PageObject.html)? Yes
? Where are your page objects located? ./test/pageobjects/**/*.js
? Which reporter do you want to use? spec
? Do you want to add a plugin to your test setup?
? Do you want to add a service to your test setup? chromedriver
? What is the base url? http://localhost
? Do you want me to run `npm install` YesIs this the correct config? No idea, but now we have wdio in our node_modules folder! However, for some reason the script still say it can’t be found, odd. Let’s have a quick look.
nano s/wdio#!/bin/bash
cd tests/e2e/
# [E2EHTTPS]
# This is old Webdriver 6, since we're in tests/e2e/ not e2e-wdio7/. [wdio_6_to_7]
cmd="node_modules/.bin/wdio wdio.conf.js $@"
echo#fca400
echo "NODE_TLS_REJECT_UNAUTHORIZED=0 $cmd"
echo
NODE_TLS_REJECT_UNAUTHORIZED=0 $cmd
exit_code=$?hm
The problem is a line 12, but line 12 excecute command from line 10. It seems like we need to fix the path for the wdio.
---- cmd="node_modules/.bin/wdio wdio.conf.js $@" ++++ cmd="../../node_modules/.bin/wdio wdio.conf.js $@"
npm install ts-node-dev@latest ts-node@latestNODE_TLS_REJECT_UNAUTHORIZED=0 ../../node_modules/.bin/wdio wdio.conf.js --only manual.2browsers --prod --deleteOldSite --localHostname=e2e-test-e1-o0-s1 --dummy-wdio-test 2022-08-26T09:10:40+00:00-tbi4yj0xt1
2022-08-26T09:10:57.609Z ERROR @wdio/config:ConfigParser: Failed loading configuration file: /home/jack/talkyard/talkyard-dev/tests/e2e/wdio.conf.js: Debug Failure. False expression: Non-string value passed to `ts.resolveTypeReferenceDirective`, likely by a wrapping package working with an outdated `resolveTypeReferenceDirectives` signature. This is probably not a problem in TS itself.Anyways, long story short, I couldn’t get the E2E test to work as I have little to no experience in dealing with npm, typescript, wdio, and whatnot. For now, I’m just gonna skip the E2E test. To do that, I need to find a way to skip it, be it deleting an entire part of a script or whatever, I’m desperate lmao. I started by looking at the Makefile, trying to see how the ‘make prod-images’ work, and how to modify it.
nano Makefile# Prod images
# ========================================
# Any old lingering prod build project, causes netw pool ip addr overlap error.
_kill_old_prod_build_project:
$(d_c) -pedt kill web app search cache rdb ;\
$(d_c) -pedt down
prod-images: _kill_old_prod_build_project
@# This cleans and builds prod_asset_bundles. [PRODBNDLS]
s/build-prod-images.sh
prod-images-only-e2e-tests: _kill_old_prod_build_project
@# This runs the e2e tests only.
s/build-prod-images.sh --skip-build
prod-images-skip-build-and-e2e-test: _kill_old_prod_build_project
@# This runs the e2e tests only.
s/build-prod-images.sh --skip-build --skip-e2e-testsHere we go! So it seems all make does is run the script at s/build-prod-images.sh. And there’s an argument that we can passthrough to skip e2e tests!
s/build-prod-images.sh --skip-e2e-testsAnd nice! Everything is built and complete! At the end of the logs you should see the message telling you how to push to image to Docker, copy and run that command if you choose to push your images to Docker Hub, which I did.
make tag-and-push-latest-images tag=v2022.09-WIP-62d044562 #our tag may differ so use the one generatedStage 6: Running the production images!
Finally! We now get to leave the development folder and go to the production folder.
cd ../talkyard-prodWe will start by doing some basic configurations. For this part I would strongly suggest that you follow the instructions on the github page. https://github.com/debiki/talkyard-prod-one
What we’re doing is just standard installation procedure of deploying Talkyard and has nothing to with our weird setup.
./scripts/prepare-ubuntu.sh 2>&1 | tee -a talkyard-maint.log
nano conf/play-framework.conf # fill in values in the Required Settings section
nano .env # type a database password
cp mem/4g.yml docker-compose.override.yml #choose accordinglyNow, onto the changes that we need to make for it to use our images. I know there is a ‘upgrade-if-needed.sh’ script but I don’t think its needed in this case. If you plan to try it out, just know that for my setup I had to change the path for docker-compose. YMMW
The part that matters is that for the .env file, we need to change the docker repository and version tag.
# Which Docker image repository to download images from. (Default is 'debiki'.) ---- DOCKER_REPOSITORY=debiki ++++ DOCKER_REPOSITORY=leejacksonz # Which version of Talkyard to use. # Don't edit manually; instead, scripts/upgrade-if-needed.sh sets it to the correct value. ---- VERSION_TAG= ++++ VERSION_TAG=v2022.09-WIP-62d044562
Once you’ve edited and saved the file, it’s ready to go! We’ll be using docker-compose to directly bring it up!
docker-compose upIn theory, everything should be running and working now! Good job!
Stage 7: Fixing Search
Now, I’ve decided to separate fixing search from the building of Talkyard. This is because we’re going to be building elasticsearch and that on its own is quite involved too. https://github.com/elastic/elasticsearch
We shall start by cloning the git, and the whole point of this whole ordeal is that we need to build an older version of elasticsearch, aka 6.8.x, as I explained previously.
cd ~
git clone -b 6.8 https://github.com/elastic/elasticsearch.git
cd elasticsearch/
./gradlew assembleThis command will build and compile all distributions of elastic search. However, you need to make sure you have java installed. For me, I used Java 11. I have not tested other versions but since Java 11 is a LTS release(that isnt too old or too recent) so I decided to use that. Otherwise you’re gonna get errors.
FAILURE: Build completed with 2 failures.
1: Task failed with an exception.
-----------
* Where:
Build file '/home/jack/elasticsearch/benchmarks/build.gradle' line: 20
* What went wrong:
A problem occurred evaluating project ':benchmarks'.
> Failed to apply plugin [id 'elasticsearch.build']
> A problem occurred starting process 'command '/usr/lib/jvm/java-11-openjdk-arm64/bin/jshell''
* Try:
Run with --stacktrace option to get the stack trace. Run with --info or --debug option to get more log output. Run with --scan to get full insights.
==============================================================================
2: Task failed with an exception.
-----------
* What went wrong:
A problem occurred configuring project ':benchmarks'.
> Must specify license and notice file for project :benchmarks
* Try:
Run with --stacktrace option to get the stack trace. Run with --info or --debug option to get more log output. Run with --scan to get full insights.
==============================================================================
* Get more help at https://help.gradle.orgsudo apt-get install openjdk-11-jdk #make sure not JRE!Make sure your ‘JAVA_HOME’ env is also configured correctly otherwise you’ll get this error. If you get this error after fixing the path, try
FAILURE: Build completed with 2 failures.
1: Task failed with an exception.
-----------
* Where:
Build file '/home/jack/elasticsearch/benchmarks/build.gradle' line: 20
* What went wrong:
A problem occurred evaluating project ':benchmarks'.
> Failed to apply plugin [id 'elasticsearch.build']
> {awt.toolkit=sun.awt.X11.XToolkit, java.specification.version=11, sun.cpu.isalist=, sun.jnu.encoding=UTF-8, java.class.path=/home/jack/.gradle/wrapper/dists/gradle-5.4.1-all/3221gyojl5jsh0helicew7rwx/gradle-5.4.1/lib/gradle-launcher-5.4.1.jar, java.vm.vendor=Ubuntu, sun.arch.data.model=64, user.variant=, java.vendor.url=https://ubuntu.com/, user.timezone=, os.name=Linux, java.vm.specification.version=11, user.country=US, sun.java.launcher=SUN_STANDARD, sun.boot.library.path=/usr/lib/jvm/java-11-openjdk-arm64/lib, sun.java.command=org.gradle.launcher.daemon.bootstrap.GradleDaemon 5.4.1, jdk.debug=release, sun.cpu.endian=little, user.home=/home/jack, user.language=en, org.gradle.appname=gradlew, java.specification.vendor=Oracle Corporation, java.version.date=2022-07-19, java.home=/usr/lib/jvm/java-11-openjdk-arm64, file.separator=/, java.vm.compressedOopsMode=32-bit, line.separator=
, java.specification.name=Java Platform API Specification, java.vm.specification.vendor=Oracle Corporation, java.awt.graphicsenv=sun.awt.X11GraphicsEnvironment, sun.management.compiler=HotSpot 64-Bit Tiered Compilers, java.runtime.version=11.0.16+8-post-Ubuntu-0ubuntu122.04, user.name=jack, path.separator=:, os.version=5.15.0-46-generic, java.runtime.name=OpenJDK Runtime Environment, file.encoding=UTF-8, jdk.tls.client.protocols=TLSv1.2, java.vm.name=OpenJDK 64-Bit Server VM, java.vendor.url.bug=https://bugs.launchpad.net/ubuntu/+source/openjdk-lts, java.io.tmpdir=/tmp, java.version=11.0.16, user.dir=/home/jack/.gradle/daemon/5.4.1, os.arch=aarch64, java.vm.specification.name=Java Virtual Machine Specification, java.awt.printerjob=sun.print.PSPrinterJob, sun.os.patch.level=unknown, java.library.path=/usr/java/packages/lib:/usr/lib/aarch64-linux-gnu/jni:/lib/aarch64-linux-gnu:/usr/lib/aarch64-linux-gnu:/usr/lib/jni:/lib:/usr/lib, java.vm.info=mixed mode, java.vendor=Ubuntu, java.vm.version=11.0.16+8-post-Ubuntu-0ubuntu122.04, sun.io.unicode.encoding=UnicodeLittle, library.jansi.path=/home/jack/.gradle/native/jansi/1.17.1/linux64, java.class.version=55.0} JAVA_HOME must be set to build Elasticsearch. Note that if the variable was just set you might have to run `./gradlew --stop` for it to be picked up. See https://github.com/elastic/elasticsearch/issues/31399 details.
* Try:
Run with --stacktrace option to get the stack trace. Run with --info or --debug option to get more log output. Run with --scan to get full insights.
==============================================================================
2: Task failed with an exception.
-----------
* What went wrong:
A problem occurred configuring project ':benchmarks'.
> Must specify license and notice file for project :benchmarks
* Try:
Run with --stacktrace option to get the stack trace. Run with --info or --debug option to get more log output. Run with --scan to get full insights.
==============================================================================export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-arm64/ #note this is only temporary
./gradlew --stop
./gradlew assembleNow the build should complete and if you check your docker images, you’ll find 3 new images.
docker image lsNow, we need to go back to the talkyard-dev folder and point the search Dockerfile to use the newly built image.
cd ~/talkyard/talkyard-dev
nano images/search/Dockerfile---- FROM docker.elastic.co/elasticsearch/elasticsearch-oss:7.10.2 ++++ FROM docker.elastic.co/elasticsearch/elasticsearch-oss:6.8.24-SNAPSHOT
We’re gonna delete the old image and ask docker-compose to rebuild it. Once done, start the dev build again.
docker image list
docker image rm IMAGEIDOFSEARCH
docker-compose build
s/tyd upAnd… nope… It seems like tyd_search_1 has exited with code 127 and app_1 is throwing out a bunch of errors cuz search ain’t working. Hmm let’s stop everything and check the logs. Ctrl+X to exit.
docker logs tyd_search_1/usr/share/elasticsearch/bin/elasticsearch-env: line 67: /opt/jdk-15.0.1+9/bin/java: cannot execute binary fileAt first I thought it had to do with the fact that this is snapshot build. After some more thinking and tinkering, I think the Java version used may be x64 specific. When I dug around the code, I found this in the build.gradle file. Elasticsearch uses Java and the binary installed is, as expected, x64. I had to dig around the GitHub release page, but thank goodness there’s an ARM version.
cd ~/elasticsearch
nano distribution/docker/build.gradle---- 'jdkUrl' : 'https://github.com/AdoptOpenJDK/openjdk15-binaries/releases/download/jdk-15.0.1%2B9/OpenJDK15U-jdk_x64_linux_hotspot_15.0.1_9.tar.gz', ++++ 'jdkUrl' : 'https://github.com/AdoptOpenJDK/openjdk15-binaries/releases/download/jdk-15.0.1%2B9/OpenJDK15U-jdk_aarch64_linux_hotspot_15.0.1_9.tar.gz',
Time to rebuild and try again.(I know this process is a little inefficient and dumb but that’s how I did it at the time).
docker image list
docker image rm docker.elastic.co/elasticsearch/elasticsearch-oss:6.8.24-SNAPSHOT
docker image rm IDOFSEARCHTYDSEARCHIMAGE
./gradlew clean
./gradlew buildOssDockerImage #this command saves time by not building the other distributions
cd ~/talkyard/talkyard-dev
docker-compose build
s/tyd upHuh, search still doesn’t work… Time to check the logs again. Ctrl+X
docker logs tyd_search_1Unrecognized VM option 'UseAVX=2'
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.After some googling, you’ll find this discussion thread.
Find the line 10-:-XX:UseAVX=2 in /etc/elasticsearch/jvm.options and comment it out or remove it (if you remove it, you can remove the comment about it too).
I had to use VS Code to help figure out where the heck is this argument at, because the forum answer seems to tell you to do it after it has been build, and that would be annoying for our docker image.
cd ~/elasticsearch
nano distribution/src/config/jvm.options---- 10-:-XX:UseAVX=2
docker image list
docker image rm docker.elastic.co/elasticsearch/elasticsearch-oss:6.8.24-SNAPSHOT
docker image rm IDOFSEARCHTYDSEARCHIMAGE
./gradlew clean
./gradlew buildOssDockerImage #this command saves time by not building the other distributions
cd ~/talkyard/talkyard-dev
docker-compose build
s/tyd upHuh, after all of that, still error again?
[2022-09-01T08:48:51,631][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [unknown] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: ElasticsearchException[java.io.IOException: failed to read [id:11, file:/usr/share/elasticsearch/data/nodes/0/_state/node-11.st]]; nested: IOException[failed to read [id:11, file:/usr/share/elasticsearch/data/nodes/0/_state/node-11.st]]; nested: XContentParseException[[-1:36] [node_meta_data] unknown field [node_version], parser not found];Some googling, you’ll learn that this occurs when you downgrade your ElasticSearch version. So what happened is that before this ES 7.x.x created its files and its stored in the volumes folder. Docker have those folders mounted in the image. So let’s delete those folders and try again.
sudo rm -rf volumes/search-data && sudo rm -rf volumes/search-logs
s/tyd upAND IT WORKS. WOOHOO! At this point I have also pushed this build of ElasticSearch to Docker Hub incase anyone needs it. https://hub.docker.com/r/leejacksonz/elasticsearch-oss
docker image tag docker.elastic.co/elasticsearch/elasticsearch-oss:6.8.24-SNAPSHOT leejacksonz/elasticsearch-oss:6.8.24-SNAPSHOT
docker push leejacksonz/elasticsearch-oss:6.8.24-SNAPSHOTIt is also possible to change the search Dockerfile again to use my own release, but that’s not very important. Now, let’s just build the production images again.
docker image list
docker image remove PRODSEARCHIMAGE
d/selenium #in case its not running
s/build-prod-images.sh --skip-e2e-tests
make tag-and-push-latest-images tag=v2022.09-WIP-62d044562 #can skip this, and will overwrite the previous one on docker hub Finally, let’s try to deploy the production images again.
cd ../talkyard-prod
docker-compose upAnd error again, but I think this is similar to what happened during the development builds. So Ctrl+X. So just gotta delete the old data files again.
docker-compose down
sudo rm -rf data/search
docker-compose upAnd I think that’s basically it folk! I believe this is basically Talkyard “production” on ARM!
Finale: Some closing words
This entire process took way longer than needed, and I’m still working on polishing the contents of this blog post. There are still some stuff that I have yet to include, like more details about the building process, the little nuances, my GitHub repo for the ARM port etc. This is my second attempt at this project, my first attempt was “successful” but I didn’t document it much. There were also quite a few things that changed, so remember, treat this post as more of a informative guide rather a instructional one.
Now, if you really wanted, you could entrust your life on my hands and just use the Talkyard ARM images I’ve already pushed to docker from this entire journey. https://hub.docker.com/u/leejacksonz I’ll also include a more streamlined step-by-step code that you can just copy paste directly and skip all these diagnosis steps.
Anyways, hope it was an entertaining read! :)